Industry 4.0 and the sensor data analytics problem
That sensor data problem
A few weeks ago, I met with a number of IT consultants who had been hired to provide data science knowledge for an Industry 4.0 project at a large German industrial company. The day I saw them they looked frazzled and frustrated. At the beginning of our meeting they spoke about the source of their frustration: ‘Grabbing a bunch of sensor data’ from a turbine had turned out to be a pretty daunting task. It had looked so simple on the surface. But it wasn’t.
Data hungry Industry 4.0
In my last blog post, I looked at the Industry 4.0 movement. It’s an exciting and worthy cause but it requires a ton of data if executed well. Sensor data (aka industrial time-series data) from various assets and control systems is key. But acquiring this type of data, processing it in real-time, archiving and managing it for further analysis turns out to be extremely problematic if you use the wrong tools. So, what’s so difficult? Here are the common problems people encounter.
1. The asset jungle
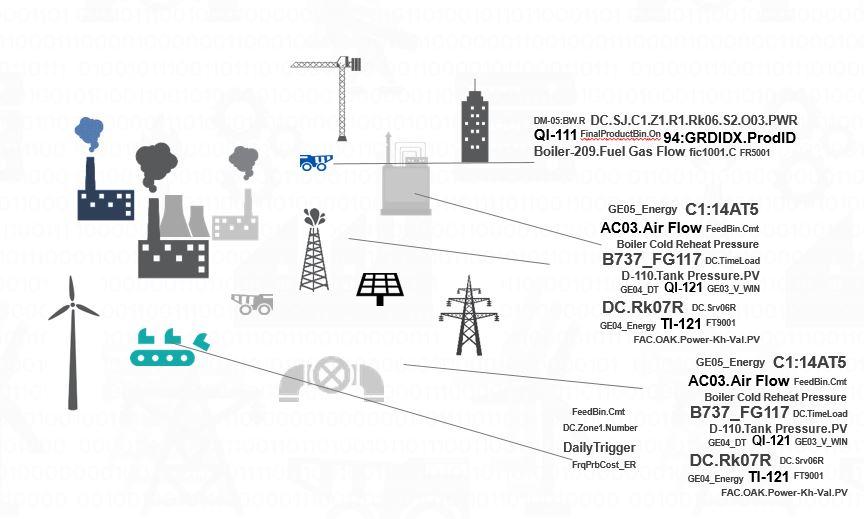
When we look at a typical industrial environment such as a packaging line, a transmission network or a chemical plant, we will find a plethora of equipment from different manufacturers, assets of different ages (it’s not unusual for industrial equipment to operate for decades), control and automation systems from different vendors (E.g. Rockwell, Emerson, Siemens, etc.). To make things worse, there is also a multitude of different communication standards and protocols such as OPC DA, IEEE C37.118 & Modbus just to name a few. As a result, it’s not easy to communicate with industrial equipment. There is no single standard. Instead, you typically need to develop and operate a multitude of interfaces. Just ‘grabbing’ a bunch of sensor data suddenly turned difficult. There is no one-size fits all.
2. Speedy data
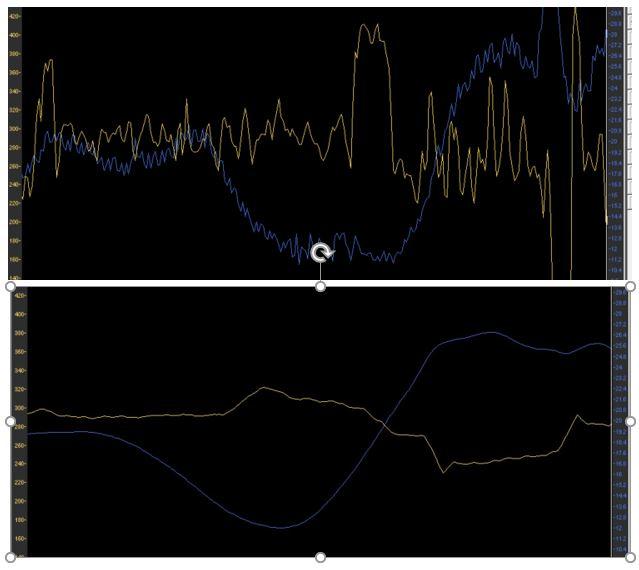
Once you have started communicating with an asset, you will find that its data can be quite fast. It’s not unusual for an asset to send data in the milisecond or second range. Capturing and processing something this fast requires special technology. Also, we do want to capture data at this resolution as it could potentially provide critical insights. And how about analyzing and monitoring that data in real-time? This is often a requirement for Industry 4.0 scenarios.
High speed data vs slow: what could you be missing?
3. Big data volumes
Not only is data super fast, it’s also big. Modern assets can easily send around 500 -10000 distinct signals or tags (e.g. bearing vibration, temperature, etc.). A modern wind turbine has 1000 plus important signals. A complex packaging machine for the pharmaceutical industry captures 300-1000 signals.
The sheer volume creates a number of problems:
Storage: Think about the volume of data that is being generated in a day, week or month: 10k signals per second can easily grow to a significant amount of data. Storing this in a relational database can be very tricky and slow. You are looking at massive amounts of TB.
Context: Sensors usually have a signal/ tag name that can be quite confusing. The local engineer might know the context, but what about the data scientist? How would she know that tag AC03.Air_Flow is related to turbine A in Italy and not pump B in Denmark?
Signal/ tag names can be extremely confusing
4. Tricky time-series
Last but not least, managing and analyzing industrial time series data is not that easy. Performing time-based calculations such as averages require specific functions that are not readily available in common tools such as Hadoop, SQL Server and Excel. To make things worse, units of measure are also tricky when it comes to industrial data. This can especially be a huge problems when you work across different regions (think about degree C vs F). You really have to make sure that you are comparing apples to apples.
5. Analytics ready data
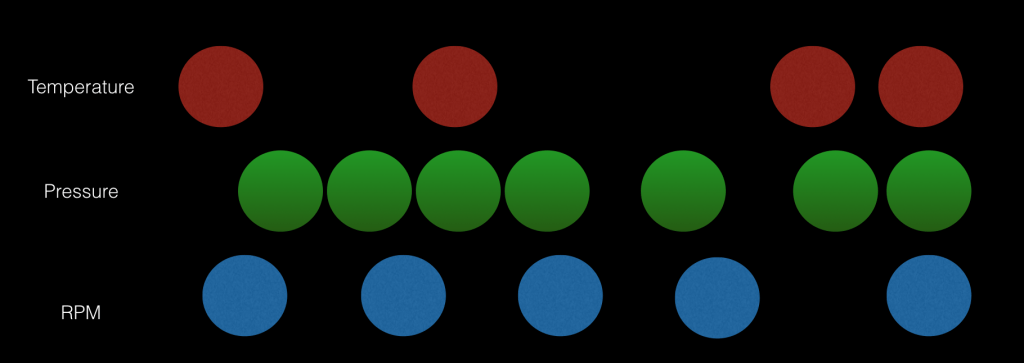
An often overlooked problem is that sensor data is not necessarily clean. Data is usually sent at uneven points in time. There might be a sensor failure or a value just doesn’t change very often. As a result you always end up with unevenly spaced data which is really hard to manage in a relational database (just google the problem). Data scientists usually require equidistant data for their analytics projects. Getting the data in the right shape can be immensely time-consuming (think about interpolations etc.).
Unevenly spaced sensor data
That tricky sensor data
To summarize this: ‘grabbing a bunch of sensor data’ is anything but easy. Industry 4.0 initiatives require a solid data foundation as discussed in my last post. Without it you run the risk of wasting a ton of time & resources. Also, chances are that the results will be disappointing. Imagine a data scientist attempting to train a predictive maintenance model with just a small set of noisy and incomplete data.
To do this properly, you need special tools such as the OSIsoft PI System. The PI System provides a unique real-time data infrastructure for all your Industry 4.0 projects. In my next post, I will describe how this works.
What are your experiences with industrial time-series data?
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.