Tag: data historian
-
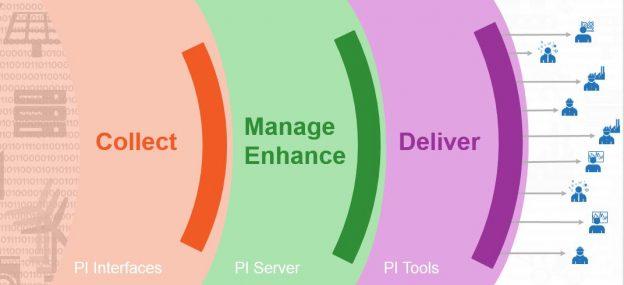
What is the OSIsoft PI System?
The OSIsoft PI System In the last two blog posts, I spoke about Industry 4.0 and the challenges around working with industrial sensor data. Let me attempt to quickyl summarize the outlined problems: Industry 4.0 initiatives require a ton of time-series data. Acquiring, managing and analyzing this can be extremely challenging. This is where the…
-

Industry 4.0 and the sensor data analytics problem
That sensor data problem A few weeks ago, I met with a number of IT consultants who had been hired to provide data science knowledge for an Industry 4.0 project at a large German industrial company. The day I saw them they looked frazzled and frustrated. At the beginning of our meeting they spoke about…